TechSEO Intelligence Hub Implementation Report
Project Context
This project was built in two days as a targeted portfolio response to a Technical SEO role that emphasizes crawlability, indexation, automation, dashboards, log/data analysis, and custom tooling. I also found a public post from Zan Ivanovic after most of the initial build was already underway, and it reinforced the same direction: a strong technical SEO workflow should not start and end with opening a standard crawler. The real value is in building the analysis, automation, and decision layer around the data.
At the same time, there was a practical constraint that made the timing oddly useful: my Screaming Frog license had expired, and renewing it was not the best option for this project. Rather than treating that as a blocker, I used it as a product constraint. LibreCrawl gave me a crawler foundation that is extensible, self-hostable, and better aligned with my current goal: build a custom monitoring and audit system that fits my own workflow instead of simply reproducing a desktop crawler export.
The result is not meant to replace every mature feature in established SEO tools. It is meant to show that I can take crawler data, define my own data contract, build repeatable audit logic, expose operational dashboards, and leave a clear path toward a native LibreCrawl extension.
Executive Summary
TechSEO Intelligence Hub is a technical SEO monitoring and audit layer built around LibreCrawl exports and future LibreCrawl plugin compatibility. The project was created to demonstrate a senior-level technical SEO workflow across crawlability, indexation, duplication, internal linking, international SEO, structured data, performance triage, and monitoring automation.
The first MVP imports LibreCrawl CSV, issue CSV, and full JSON exports, normalizes them into a plugin-compatible data contract, runs rule-based audits, stores the results in a local analytical database, and exports automation-ready JSON, CSV, and Markdown reports.
Dashboard Choice
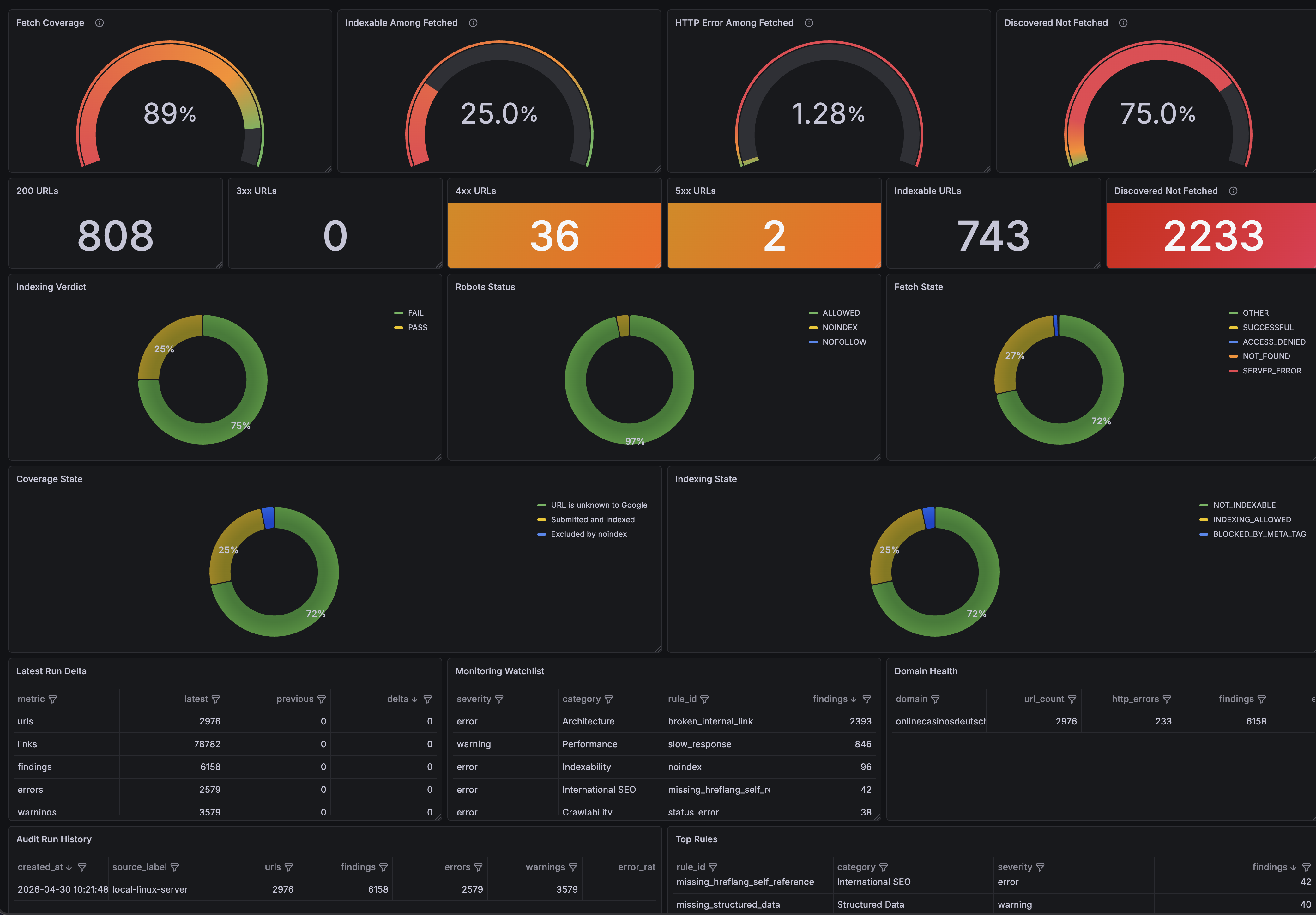
For the dashboard layer, I intentionally chose Grafana instead of Looker Studio, Power BI, or an Excel/Power Query workflow. There was no single complicated reason. Grafana simply fits the monitoring direction of this project better: it is lightweight, open source, good for recurring operational views, supports flexible queries and multiple datasource types, and is easy to connect to both API-style data and future time-series metrics.
There is also a smaller but real product reason: Grafana dashboards are visually clear, colorful, and enjoyable to use. That matters more than it may sound. A monitoring product is more likely to be used regularly if it feels fast, readable, and engaging rather than like another spreadsheet export.
The current dashboards are already implemented, including an executive overview, domain health, issue explorer, indexation-style views, monitoring tables, and Prometheus-ready metrics. However, the current crawl should be treated as a pipeline validation run rather than a final SEO conclusion. The first crawl still contains a large number of unfetched or partially evaluated URLs, so some issue counts reflect crawl coverage limitations rather than confirmed site defects.
For that reason, the next step is to improve crawl stability through the Linux server setup, proxy/VPN routing where appropriate, and clearer fetch-state classification before using the dashboard as final evidence for SEO recommendations.
Why LibreCrawl Was Selected
LibreCrawl was selected over a traditional Screaming Frog-centered workflow because it is better aligned with the long-term direction of this project:
-
Extensibility:
LibreCrawl is open source and supports a browser-side plugin model. This makes it possible to build custom technical SEO analysis views instead of being limited to predefined exports or external post-processing. -
Automation potential:
LibreCrawl exposes structured crawl data and an API-oriented workflow, which fits scheduled monitoring, server-side crawls, and integration with automation platforms such as n8n, Make, Zapier, and MCP-based workflows. -
Large-site direction:
LibreCrawl is designed as a modern web application with attention to memory profiling, virtual scrolling, multi-session usage, and self-hosted operation. This makes it a stronger foundation for high-URL-count monitoring than a desktop-only workflow. -
Data ownership:
Running the crawler on owned infrastructure keeps crawl data, competitive analysis, and future monitoring history under direct control. -
Plugin future:
The ability to add custom tabs and analysis logic creates a path from an external Python audit layer into a native LibreCrawl plugin.
Screaming Frog remains a mature and widely used technical SEO crawler, and familiarity with Screaming Frog CLI is still valuable. However, for this project the goal is not only to run audits, but to build a reusable monitoring product. LibreCrawl is a better fit for that product direction because it can be extended, hosted, and automated more naturally.
Current Operating Model
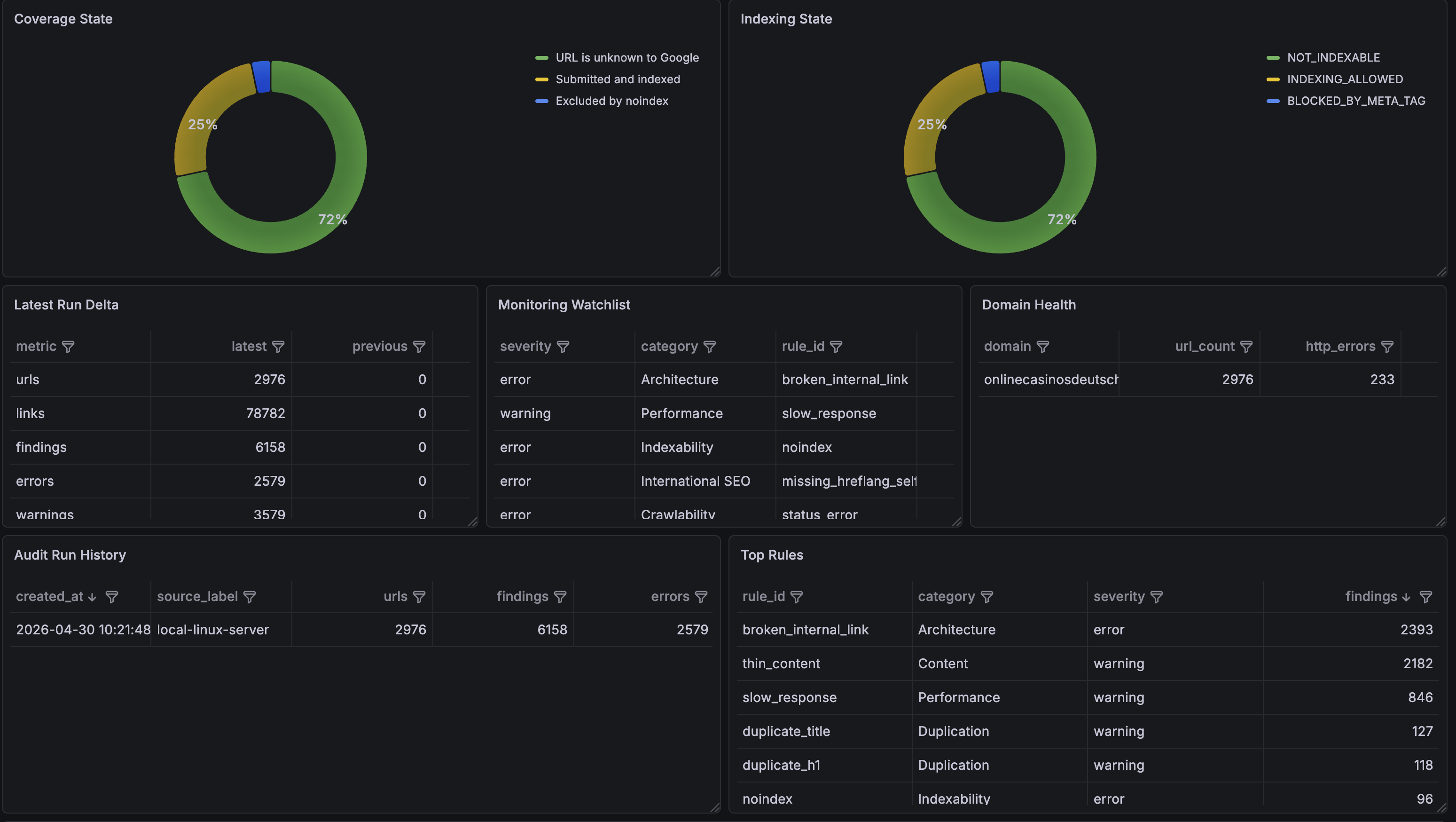
The current crawl workflow is already server-oriented. LibreCrawl is run from a Linux server at home, and crawl exports are used as the input for the TechSEO Intelligence Hub analysis layer.
This setup is intentionally close to the future production model:
- A Linux server runs LibreCrawl for selected domains.
- LibreCrawl exports CSV, issue CSV, and full JSON crawl data.
- TechSEO Intelligence Hub imports the exported data.
- Audit rules generate findings, domain health scores, and executive summaries.
- Reports are exported for dashboards, LLM-assisted triage, and automation workflows.
- Future scheduled jobs can run the same process periodically across a portfolio of domains.
The local Linux server model is important because it proves that the workflow is not dependent on manual desktop crawling. It can evolve into a recurring monitoring system that runs independently and produces consistent outputs.
Product Direction
The MVP is intentionally implemented as an external audit application before becoming a LibreCrawl plugin. This keeps the architecture practical while preserving the plugin path.
The system has three layers:
-
LibreCrawl data layer:
crawl execution, URL discovery, link extraction, issue extraction, and raw exports. -
TechSEO intelligence layer:
normalization, rule evaluation, scoring, trend-ready summaries, and automation outputs. -
Presentation and automation layer:
Grafana dashboards, JSON summaries for workflow tools, Markdown briefs for human review, and future LibreCrawl plugin tabs.
This separation makes the project easier to maintain. The same audit rules can run against historical exports, scheduled server crawls, or eventually live LibreCrawl plugin data.
Senior Technical SEO Capabilities Demonstrated

The project maps directly to recurring senior technical SEO responsibilities:
-
Crawlability and indexation:
HTTP status, canonical, robots directives, noindex, nofollow, and crawl error detection. -
Duplication:
duplicate title, meta description, H1, canonical consolidation, and thin-content candidates. -
Architecture and internal linking:
internal link graph analysis, broken internal links, link placement, and orphan candidates. -
International SEO:
language and hreflang self-reference validation. -
Structured data:
JSON-LD and schema.org detection with future page-type validation. -
Performance triage:
response time and page size as first-pass indicators, with PageSpeed Insights and CrUX planned as enrichment sources. -
Dashboard migration:
replacing manual Excel and Power Query reporting with repeatable database-backed exports and Grafana-ready tables. -
Automation:
JSON and Markdown outputs suitable for workflow tools and LLM-assisted prioritization.
Future Expansion

The next phase should focus on scheduled monitoring and tighter LibreCrawl integration:
- Run scheduled crawls on the Linux server.
- Add a LibreCrawl API adapter for crawl start, status polling, and export retrieval.
- Store historical crawl runs for trend analysis.
- Add PageSpeed Insights or CrUX enrichment for Core Web Vitals.
- Add server log imports to compare crawl behavior with search engine bot activity.
- Create a native LibreCrawl JavaScript plugin tab using the existing plugin contract.
- Add notification workflows for high-severity changes, such as sudden noindex spikes, broken template links, hreflang regressions, or response-time degradation.
Conclusion
TechSEO Intelligence Hub is not only a report generator. It is the foundation for a self-hosted technical SEO monitoring product. LibreCrawl provides the extensible crawler base, the Linux server provides an automation-ready execution environment, and the Python audit layer provides the domain-specific intelligence needed to turn crawl data into prioritized technical SEO action.